
干货教程
1、Dify 的部署与使用
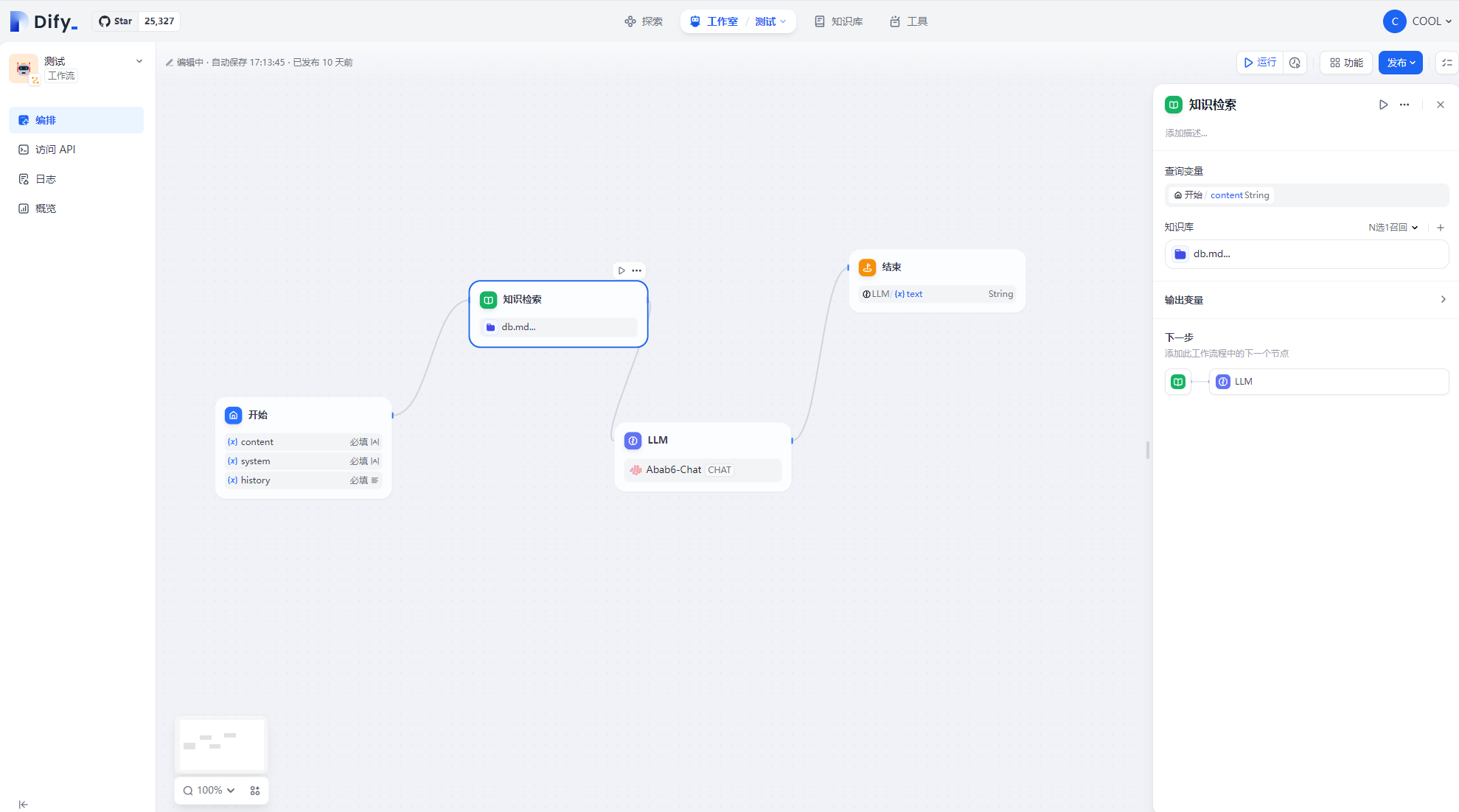
Dify,是一个用于开发 Ai 应用的工具,支持知识库,流程编排,向量检索,并可接入多种模型。
2、Ollama 介绍与使用
ollama是一个开源的可以运行多种模型的工具,如:llama、qwen、mistral 等,除了聊天模型,还支持向量化模型,可以将文本转换为向量,具体可以到官网查看:https://ollama.com/
Ollama 结合 Chroma、Cool 构建智能微信机器人客服视频教程
3、LLAMA3 微调与部署
unsloth,是一个快速微调 Mistral,Gema,Llama 等模型的工具,速度提高 2-5 倍,内存减少 80%!
注意
建议在 Linux 环境下使用,否则可能你需要处理各种各样的奇怪的问题
安装完 conda 后,执行以下命令即可安装 unsloth:
conda create --name unsloth_env python=3.10
conda activate unsloth_env
conda install pytorch-cuda=<12.1/11.8> pytorch cudatoolkit xformers -c pytorch -c nvidia -c xformers
pip install "unsloth[colab-new] @ git+https://github.com/unslothai/unsloth.git"
pip install --no-deps trl peft accelerate bitsandbytes
安装过程需要耐心等待,大部份问题都是由于网络问题导致的,如果遇到问题,可以尝试多次安装,或者使用代理。
微调脚本train.py:
from unsloth import FastLanguageModel
import torch
from trl import SFTTrainer
from transformers import TrainingArguments
max_seq_length = 2048 # Choose any! We auto support RoPE Scaling internally!
dtype = None # None for auto detection. Float16 for Tesla T4, V100, Bfloat16 for Ampere+
load_in_4bit = True # Use 4bit quantization to reduce memory usage. Can be False.
model, tokenizer = FastLanguageModel.from_pretrained(
# More models at https://huggingface.co/unsloth
model_name = "unsloth/llama-3-8b-bnb-4bit",
max_seq_length = max_seq_length,
dtype = dtype,
load_in_4bit = load_in_4bit,
# token = "hf_...", # use one if using gated models like meta-llama/Llama-2-7b-hf
)
model = FastLanguageModel.get_peft_model(
model,
r = 16, # Choose any number > 0 ! Suggested 8, 16, 32, 64, 128
target_modules = ["q_proj", "k_proj", "v_proj", "o_proj",
"gate_proj", "up_proj", "down_proj",],
lora_alpha = 16,
lora_dropout = 0, # Supports any, but = 0 is optimized
bias = "none", # Supports any, but = "none" is optimized
# [NEW] "unsloth" uses 30% less VRAM, fits 2x larger batch sizes!
use_gradient_checkpointing = "unsloth", # True or "unsloth" for very long context
random_state = 3407,
use_rslora = False, # We support rank stabilized LoRA
loftq_config = None, # And LoftQ
)
alpaca_prompt = """Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
{}
### Input:
{}
### Response:
{}"""
EOS_TOKEN = tokenizer.eos_token # Must add EOS_TOKEN
def formatting_prompts_func(examples):
instructions = examples["instruction"]
inputs = examples["input"]
outputs = examples["output"]
texts = []
for instruction, input, output in zip(instructions, inputs, outputs):
# Must add EOS_TOKEN, otherwise your generation will go on forever!
text = alpaca_prompt.format(instruction, input, output) + EOS_TOKEN
texts.append(text)
return { "text" : texts, }
pass
from datasets import load_dataset
file_path = "data.json"
dataset = load_dataset("json", data_files={"train": file_path}, split="train")
dataset = dataset.map(formatting_prompts_func, batched = True,)
trainer = SFTTrainer(
model = model,
tokenizer = tokenizer,
train_dataset = dataset,
dataset_text_field = "text",
max_seq_length = max_seq_length,
dataset_num_proc = 2,
packing = False, # Can make training 5x faster for short sequences.
args = TrainingArguments(
per_device_train_batch_size = 2,
gradient_accumulation_steps = 4,
warmup_steps = 5,
max_steps = 60,
learning_rate = 2e-4,
fp16 = not torch.cuda.is_bf16_supported(),
bf16 = torch.cuda.is_bf16_supported(),
logging_steps = 1,
optim = "adamw_8bit",
weight_decay = 0.01,
lr_scheduler_type = "linear",
seed = 3407,
output_dir = "outputs",
),
)
trainer_stats = trainer.train()
# alpaca_prompt = Copied from above
FastLanguageModel.for_inference(model) # Enable native 2x faster inference
inputs = tokenizer(
[
alpaca_prompt.format(
"Continue the fibonnaci sequence.", # instruction
"1, 1, 2, 3, 5, 8", # input
"", # output - leave this blank for generation!
)
], return_tensors = "pt").to("cuda")
from transformers import TextStreamer
text_streamer = TextStreamer(tokenizer)
_ = model.generate(**inputs, streamer = text_streamer, max_new_tokens = 128)
model.save_pretrained("lora_model") # Local saving
# 保存模型为gguf
# model.save_pretrained_gguf("model", tokenizer, quantization_method = "q4_k_m")
inputs = tokenizer(
[
alpaca_prompt.format(
"介绍下COOL团队", # instruction
"", # input
"", # output - leave this blank for generation!
)
], return_tensors = "pt").to("cuda")
from transformers import TextStreamer
text_streamer = TextStreamer(tokenizer)
_ = model.generate(**inputs, streamer = text_streamer, max_new_tokens = 128)
要好的效果,你得认真准备你要训练的数据集,
数据集格式如下,instruction 为提示,input 为输入,output 为输出:
data.json
[
{
"instruction": "COOL官网",
"input": "",
"output": "COOL官网是:https://cool-js.com"
}
]
4、LM Studio 介绍
LM Studio是一个可以运行多种模型的工具,如:llama、qwen、mistral 等,除了聊天模型,还支持向量化模型,可以将文本转换为向量,具体可以到官网查看:https://lmstudio.ai/
5、huggingface 镜像站推荐
在做 Ai 应用开发或者学习的时候,我们经常需要下载各种模型,而 huggingface 的模型下载速度很慢或者根本就连不上,这里推荐一个 huggingface 的镜像站,速度很快,可以大大提高我们的效率。
推荐一个 huggingface 的镜像站:https://hf-mirror.com/
示例
pip install -U huggingface_hub
import os
// 设置环境变量,下载器就会使用镜像站
os.environ["HF_ENDPOINT"] = "https://hf-mirror.com"
from transformers import AutoTokenizer, AutoModelForCausalLM
model_id = "shenzhi-wang/Llama3-8B-Chinese-Chat"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id, torch_dtype="auto", device_map="auto"
)
messages = [
{"role": "system", "content": "你是诗仙,很会做诗"},
{"role": "user", "content": "写一首关于COOL团队的诗"},
]
input_ids = tokenizer.apply_chat_template(
messages, add_generation_prompt=True, return_tensors="pt"
).to(model.device)
outputs = model.generate(
input_ids,
max_new_tokens=8192,
do_sample=True,
temperature=0.6,
top_p=0.9,
)
response = outputs[0][input_ids.shape[-1] :]
print(tokenizer.decode(response, skip_special_tokens=True))